
Optimizing your website's crawl budget is key if you want search engines to quickly find and index your content.
In this guide, we'll dive into crawl budgets and share some practical tips to help you boost your site's visibility in search results.
What's a Crawl Budget?
A crawl budget is basically the number of pages or URLs that a search engine bot, like Googlebot, crawls and indexes on your site within a set period.
It's like the bot's resources allocated to your site, balancing the need to keep up with new content without putting too much strain on your server.
A crawl budget is like a delivery driver with a set number of hours to make deliveries across a city.
They need to prioritize which packages (pages or URLs) to deliver (crawl) first, based on importance and urgency, while making sure not to overload their vehicle (server).
If there are too many stops or if the routes are inefficient, they might not be able to deliver everything within their shift, and some packages may be left for the next day.
Similarly, the bot has to balance crawling your site without overwhelming it, ensuring that important pages get crawled in time.
Why is Crawl Budget Important?
Your site's crawl budget determines how often search engines visit and index your pages, which can have a direct impact on your SEO.
Managing it well ensures search engines focus on the right pages, helping your site perform better in search results.
Let's break down why it matters:
1. Indexation Efficiency
If search engines don't index a page, it won't show up in search results, which can hurt your SEO efforts.
Proper crawl budget management ensures that your most important pages-those that need visibility-are crawled and indexed first, giving them a better chance to rank and be seen.
2. Relevant for All Site Sizes
Crawl budget issues aren't just for huge sites.
Even smaller websites can run into trouble, especially if they have technical problems like duplicate content, broken links, or server errors. No matter the size, keeping an eye on how efficiently your pages are being crawled is important.
3. Server Performance
Bots crawling your site can put pressure on your server. If they request too many pages at once, it could slow things down or even cause downtime.
Managing your crawl budget helps distribute these requests more smoothly, keeping your server healthy and preventing crashes.
4. Better SEO Optimization
When you manage your crawl budget well, search engines focus on your high-priority pages-the ones that matter most for rankings.
This prevents them from wasting time on less important or outdated content, boosting your overall SEO and ensuring that your best content is being crawled first.
How Search Engines Crawl the Web
Search engines use bots (aka crawlers or spiders) to browse the web. They follow links from one page to another and index the content they find. This process is based on two main factors:
Crawl Capacity Limit
This refers to how fast a bot can request pages from your site without overwhelming your server. A site with faster server response times can handle more crawl requests, while a slower or overloaded server may limit how often pages get crawled.
Crawl Demand
Bots also decide which pages to prioritize based on their demand. This demand depends on things like how popular a page is or how frequently it's updated. Pages that are visited more often or have fresh content tend to get crawled more frequently, while older or less relevant pages might not be crawled as often.
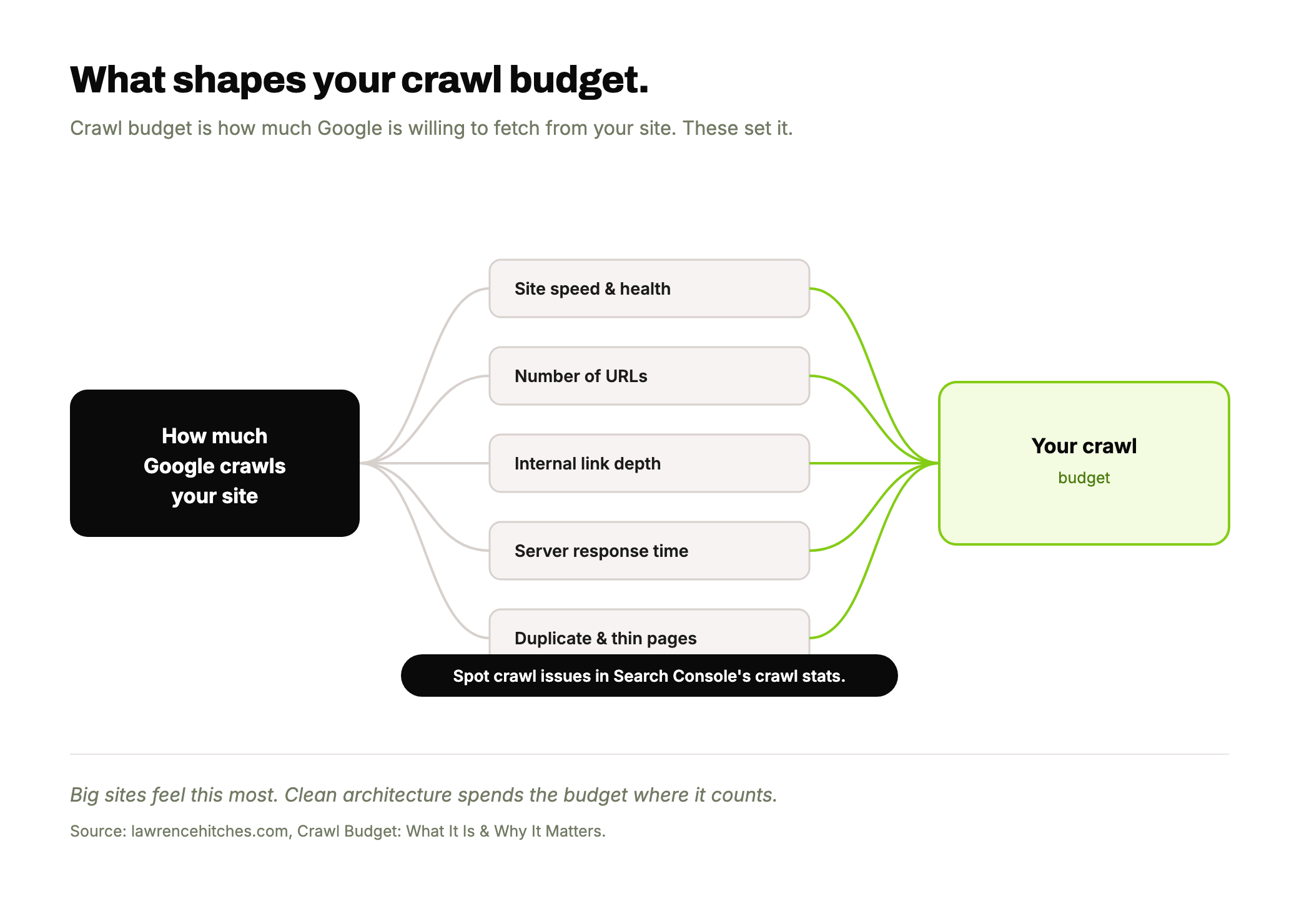
Factors That Affect Crawl Budget
1. Crawl Capacity Limit
This refers to how many requests a crawler can make to your site without causing problems. Here's what impacts that:
- Server Performance: A faster, more responsive server can handle more crawl requests.
- Error Rates: If your site has a lot of server errors (like 5xx responses), Google may slow down crawling.
- Crawl Health: The more stable your server is, the more comfortable Googlebot feels crawling it.
- Hosting Quality: Cheaper hosting can lead to connectivity issues, which can hurt your crawl capacity.
2. Crawl Demand
Crawl demand depends on what the bot sees as worth crawling:
- Total URLs: If Google knows about too many URLs (especially low-value or duplicate ones), it can waste your crawl budget.
- Page Popularity: Pages that are popular or have lots of links pointing to them get crawled more often.
- Content Freshness: The more you update a page, the higher the crawl demand for it.
- Old Content: Outdated or less relevant pages may not be crawled as frequently.
Spotting Crawl Issues with Google Search Console
Google Search Console's Crawl Stats Report gives you a clear view of how Googlebot is crawling your site. Here's how to access it:
- Log into Google Search Console.
- Go to the "Settings" section.
- Under "Crawling," click "Open Report" next to "Crawl stats."
You'll see data like:
- Total Requests: How many crawl requests Googlebot made.
- Download Size: The total amount of data downloaded during the crawling.
- Average Response Time: How fast your server responded to those requests.
- Host Status: Any issues Googlebot ran into while crawling.
Host Status breakdown:
- Dark Green: Everything's good; crawling is smooth.
- Light Green: Some minor issues, but nothing major.
- Red: Big problems that need fixing right away.
Common Crawl Issues to Watch For
Best Practices for Optimizing Crawl Budget
Optimizing your crawl budget involves more than just basic techniques. These advanced strategies ensure that search engine crawlers navigate your site efficiently, improving SEO and maximizing crawl potential.
Advanced Crawl Budget Strategies
1. JavaScript Rendering Optimization
Websites that rely heavily on client-side JavaScript can pose challenges for search engine crawlers. Since these crawlers need to process the JavaScript to access the content, it consumes extra resources and can slow down the crawling process. By utilizing server-side rendering (SSR) or dynamic rendering, crawlers can more easily access pre-rendered content, resulting in faster and more efficient crawling.
2. HTTP/2 Protocol Upgrade
HTTP/2 is a modern protocol that enhances how resources are delivered across the web. It allows multiple files to be transferred simultaneously over a single connection. This increases the efficiency of crawlers by enabling them to retrieve more resources in less time, which leads to faster and more comprehensive crawling of your site.
3. Sitemap Index Files for Large Websites
Large websites with thousands of pages can run into limitations with standard XML sitemaps, which cap out at 50,000 URLs. By using sitemap index files, large sites can split their URLs across multiple sitemaps, helping search engines systematically discover and prioritize content. This technique ensures that all important areas of the site are crawled without overwhelming search engines.
4. Correct Hreflang Tag Implementation
For international or multilingual websites, improperly configured hreflang tags can cause duplicate content issues. This leads to crawlers wasting time indexing multiple versions of the same content. Correct implementation of hreflang tags helps guide search engines to the appropriate language or regional version of a page, improving both crawl efficiency and user experience.
5. Managing Faceted Navigation
Faceted navigation-common in e-commerce websites-can generate countless URL combinations based on filter choices. While useful for users, many of these variations offer little unique content and can consume crawl budget unnecessarily. By carefully controlling which facets are crawled, websites can ensure that crawlers focus on the most valuable content and avoid duplicate or low-value pages.
6. Optimizing Single-Page Applications (SPAs) and API-Driven Sites
Single-page applications and sites that load content dynamically via APIs can pose problems for crawlers, as the content may not be immediately visible for indexing. These sites benefit from techniques like pre-rendering or hybrid rendering, which allow search engines to access the full content upon initial load, minimizing the need for multiple rendering passes and making more efficient use of crawl budget.
7. Log File Analysis
Log file analysis is a powerful tool for understanding how crawlers interact with your site. By reviewing server logs, website owners can see which pages are frequently crawled and which are being overlooked. This insight helps identify potential crawl inefficiencies and enables site owners to adjust their internal linking structure or update XML sitemaps to better allocate crawl budget.
8. Leveraging Structured Data Markup
Structured data, such as Schema.org markup, provides search engines with additional context about the content on your site. While it doesn't directly impact the crawl budget, structured data helps crawlers understand your content more effectively, which can improve crawl frequency and overall site indexing.
9. Mobile Optimization for Mobile-First Indexing
With Google's mobile-first indexing, the mobile version of a website is the primary one used for crawling and indexing. Ensuring that your mobile site is well-optimized, with no crawl barriers such as blocked resources or poor navigation, is crucial for maintaining crawl efficiency and achieving strong rankings under this indexing model.
10. Securing Admin and Backend URLs
Exposing non-public URLs, like admin dashboards or backend endpoints, can not only create security risks but also waste valuable crawl budget. Crawlers might spend time accessing these areas instead of focusing on your public-facing content. Keeping these URLs hidden from crawlers preserves resources for more important pages.
11. Monitoring Crawl Stats via APIs
APIs, such as the Google Search Console API, allow for automated monitoring of crawl statistics. This provides detailed, real-time insights into how crawlers interact with your site, helping to identify patterns or issues that may affect your crawl budget. Regular monitoring helps ensure that crawlers are being used efficiently.
12. Balancing Security Measures with Crawl Accessibility
Overly strict security settings, such as CAPTCHAs or firewalls, can sometimes prevent legitimate search engine crawlers from accessing your site. While security is important, it's equally crucial to ensure that trusted crawlers like Googlebot can still index your content. Balancing security with crawl accessibility is essential for maintaining crawl efficiency without compromising site safety.
What to Do If You Have Crawl Issues
If you're facing serious crawl problems:
- Server Issues: Check your logs for errors and work with your hosting provider to solve performance issues.
- Robots.txt and DNS Fixes: Make sure your robots.txt file is accessible and your DNS settings are correct.
- Monitoring: Use Google Search Console to test live URLs and robots.txt, and keep an eye on crawl stats to make sure issues are resolved.
The 2026 Update: AI Crawlers Eat Crawl Budget Too
The biggest change to crawl budget management since 2024: AI crawlers now consume meaningful crawl budget on most sites. GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, Google-Extended, Bytespider, and Meta-ExternalAgent all hit your site to refresh their training and retrieval indexes. On large sites, AI crawlers can collectively consume 20-40% of total crawl activity.
What this changes:
- Server budget matters more. Even sites that previously had crawl budget headroom can hit limits when AI crawlers ramp up activity. Monitor server logs for crawler activity by user agent.
- Robots.txt for AI crawlers is now part of crawl budget management. Decide whether AI crawlers should access your full site, a subset, or be blocked entirely. Coverage in our robots.txt guide.
- Cloudflare WAF and AI bot management tools now offer separate controls for AI crawlers vs. search engine crawlers. For high-traffic sites, this is the cleaner control point than robots.txt alone.
- The opt-out trade-off: blocking AI crawlers means zero presence in ChatGPT, Claude, Perplexity, and other AI search engines. For most content businesses, allowing AI crawlers is the right call, but it's a budget trade-off.
How to Audit AI Crawler Activity on Your Site
- Pull server access logs for the last 30 days
- Group requests by User-Agent string (look for GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, etc.)
- Calculate AI crawler share of total bot traffic
- If AI crawlers exceed 30% of bot activity AND you're seeing crawl issues in Google Search Console, consider rate-limiting or selective blocking
Final Word
Mastering your site's crawl budget is a must if you want to improve your SEO. Whether your site is large or small, understanding how crawlers interact with your pages and following these best practices can help you get more visibility, offer a better user experience, and attract more organic traffic.
Crawl Budget Frequently Asked Questions
1. What is the benefit of using HTTP/2 for crawl budget optimization?
HTTP/2 allows for multiple files to be downloaded at once over a single connection, improving efficiency for crawlers. This reduces the time it takes search engine bots to fetch your resources, allowing more pages to be crawled in less time. For large websites, this means faster and more thorough crawling, ultimately benefiting SEO.
2. How does JavaScript rendering affect my crawl budget?
Sites that rely heavily on client-side JavaScript can slow down search engine crawlers since they need to execute the JavaScript to access the content. This extra processing uses up resources, which can limit the number of pages crawled. Optimizing your site with server-side rendering (SSR) or dynamic rendering helps ensure that crawlers access pre-rendered content, saving resources and improving crawl efficiency.
3. Why should I use structured data markup to improve crawling?
While structured data doesn't directly change how your crawl budget is used, it helps search engine crawlers better understand the content on your site. By providing extra context through Schema.org markup, you can increase the perceived value of your pages, which may lead to more frequent crawling and improved indexing, particularly for rich snippets or enhanced search results.
Sources & Further Reading
Soaring Above Search
Weekly AI search insights from the front line. One newsletter. Six sections. Everything that actually moved this week, with a practitioner's take.

Chief of Staff at StudioHawk, Australia's largest dedicated SEO agency. Specialising in AI search visibility, technical SEO, and organic growth strategy. Leading a team of 120+ across Melbourne, Sydney, London, and the US. Book a free consultation →