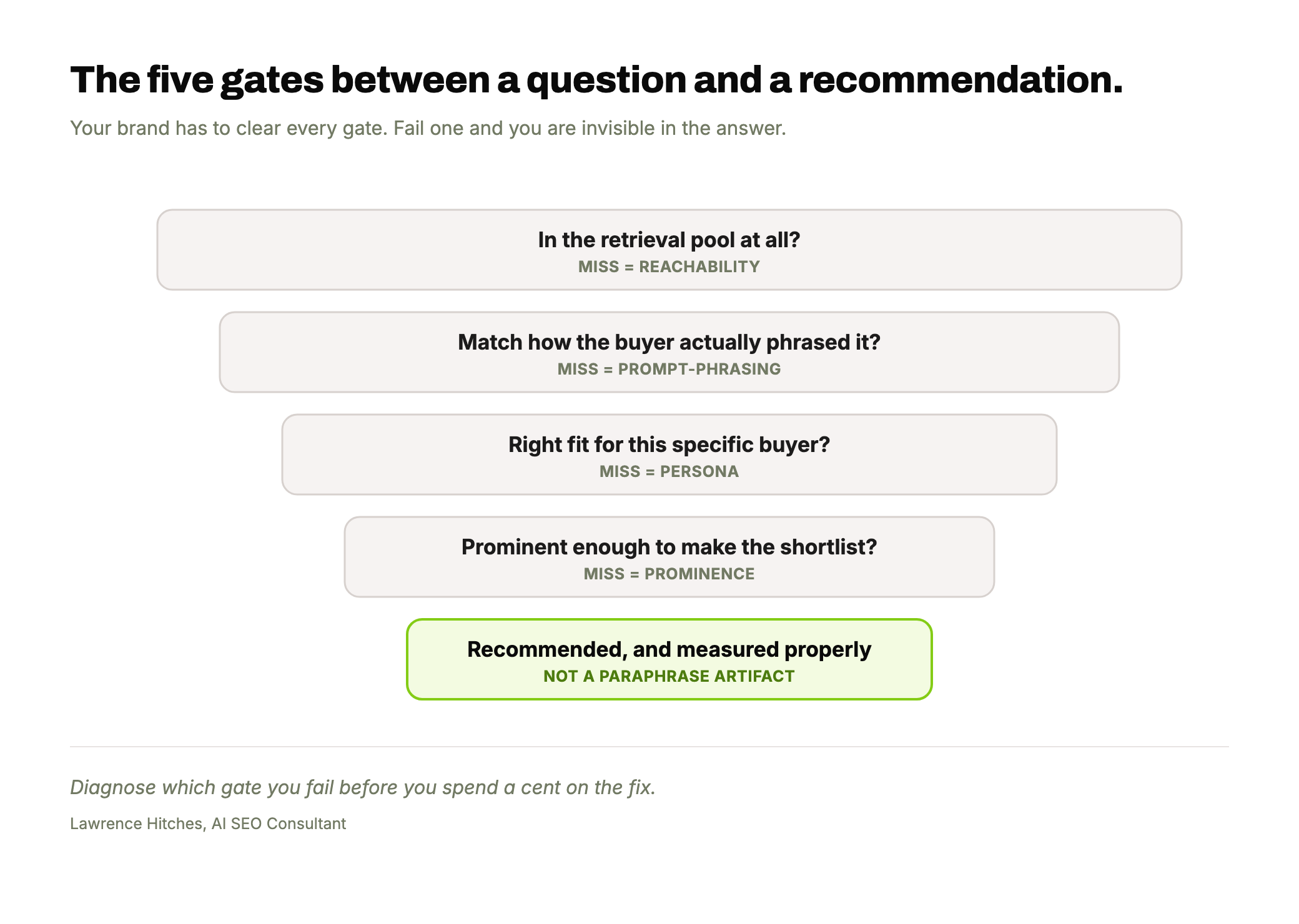
AI does not recommend your brand for one of five distinct reasons, and each needs a different fix. Either it cannot discover you for the query, it discovers you but you lose the shortlist, it names you but does not pick you, it recommends you to the wrong buyer, or it only recommends you for one phrasing of the question. Being in the model is not the problem. Being recommended is. Most campaigns fail because they treat all five as the same problem.
Being in the model is not the same as being recommended
Every founder and CMO experimenting with AI search has the same experience. ChatGPT knows their brand exists. Claude describes what they do accurately if you ask it directly. Perplexity cites their site. And yet the moment a buyer asks "best CRM for a Series A SaaS" or "top project management tool for agencies," their brand is nowhere. Someone else gets recommended.
Here is the uncomfortable answer I give in every discovery call. Being in the model is table stakes. Almost every brand of a certain size is already in there. Being in the model is not the leverage. Getting recommended at the moment of decision is a completely different problem, and it is the one that moves revenue.
In the work I do with brands trying to win AI visibility, I have found there are five distinct reasons AI does not recommend you. Each one requires different work to fix. Most agencies conflate them into one vague "AEO" bucket, and that is exactly why most AEO and GEO campaigns underperform. You cannot fix a problem you have not diagnosed.
Let me make it concrete. Picture a project management tool that gets mentioned in a healthy share of AI answers for its category. The founder is happy, the agency is happy, the dashboard is green. But split that number by buyer and it can invert entirely: recommended constantly to solo users, almost never to the agency buyers who actually pay the invoices. The headline number looks like success and hides the real failure. That is a persona problem in the wild, and no volume of extra blog content touches it.
The five failure modes
This is the taxonomy I use. When a brand is invisible in AI answers, it is failing at one of these five points, and usually one is dominant. Name the dominant one and the fix becomes obvious. Skip the diagnosis and you spend on the wrong lever.
| The failure mode | What it means | The fix |
|---|---|---|
| Discoverability | AI does not know you exist for this query. You are never in the candidate pool it pulls before it answers. | Get indexed, rank for the underlying searches, earn placement on the authority lists AI reads. |
| Reachability | You are in the pool, but you lose the shortlist when the model compares snippets. | Depth, differentiation, evidence and proof that survive the comparison. |
| Positioning | AI names you, but as a foil, not the pick. You are "one of the options," never the answer. | Sharpen the product-fit narrative and the messaging the model needs to put you first. |
| Persona | AI recommends you, but to the wrong buyer. The right buyer gets routed elsewhere. | Persona-conditioned content: different pages, case studies and narratives per buyer type. |
| Prompt-phrasing | You win one phrasing of the query and vanish on the next natural rewording. | Cover the underlying intent across the full paraphrase surface, not a single phrasing. |
The Discoverability failure is the floor. AI does not know you exist for this query because the retrieval layer never surfaces your domain when the model runs its background searches. You are not in the candidate pool at all. This is a technical and authority problem: get indexed, rank for the underlying searches, and get onto the lists AI reads when it builds its shortlist.
The Reachability failure is subtler. Your page makes the candidate pool, but when the model reads your snippet against the alternatives, you do not survive the comparison. This is a depth and evidence problem. The fix is content that out-proves the competition at the moment of shortlist, not more content in general.
The Positioning failure is the one that frustrates strong brands most. AI mentions you, but as a foil. You show up "along with X, Y and Z," never as the answer. You are furniture in the category, not the recommendation. The fix is positioning and product-fit narrative: giving the model the specific reason to put you first.
The Persona failure is invisible until you look for it. The same query from a solo founder and an enterprise VP produces materially different recommendation sets. If your marketing is not persona-aware, the model has nothing to route the right buyer to you with. The fix is persona-conditioned architecture: different landing pages, case studies and narratives per buyer type.
The Prompt-phrasing failure is a coverage problem masquerading as a brand problem. You get recommended for "best CRM" but not "top CRM," "best CRM software 2026," or "CRM for SaaS teams." Same buyer, same intent, two natural phrasings, completely different answers. The fix is answering the underlying intent across the full paraphrase surface, not optimising a single phrasing.
The prominence trap: why most agencies get this wrong
Here is the part almost nobody accounts for. Which failure mode is hurting you depends on where your brand sits on the prominence ladder in your category. The same intervention that saves a regional specialist is a waste of money for a category leader. Treating every client the same is the core mistake in the market.
| Prominence tier | Dominant failure mode | The lever |
|---|---|---|
| Category leaders | Positioning, sometimes Reachability. Never Discoverability. | Sharper positioning. More content will not help you. |
| Established challengers | Positioning, by segment. Highest conversion tier once retrieved. | Own a persona. Segment-targeted positioning. |
| Mid-market | All five, live at once. The messy middle. | Hybrid investment. Diagnose before you spend. |
| Long-tail and regional | Discoverability, first and mostly. | Authority-list seeding and regional-signal building. |
If you are a category leader, discoverability is solved. When you underperform in AI it is almost always positioning, occasionally reachability, and adding more content will do nothing. If you are an established challenger, you are in the highest-conversion tier once you get retrieved, and the lever is segment-targeted positioning. Own a persona and the model routes those buyers to you.
The mid-market is the messy middle, where all five failure modes are live at once and hybrid investment matters most. This is where most serious clients actually sit, and where a blind spend does the most damage. Long-tail specialists and regional players have one dominant problem: discoverability. You are simply not in the retrieval pool for most relevant queries, so the leverage is authority-list seeding and regional-signal building, not positioning polish.
This is why a single "AI SEO package" priced the same for every client is a red flag. A category leader and a regional specialist have nearly opposite problems. Sell them the identical content-heavy retainer and at least one is buying a fix for a failure they do not have. The tier decides the diagnosis, the diagnosis decides the lever, and the lever decides where the money goes. Reverse that order, which is what most of the market does, and you are guessing with a dashboard for cover.
Why the AEO tools you are paying for do not diagnose this
Most AI visibility trackers on the market today do one thing. They issue a small fixed set of prompts on a schedule, count how often your brand gets mentioned, and hand you a rank-style dashboard. This looks like measurement. It is not, and here is the plain-language reason.
The same buyer intent phrased two natural ways produces recommendation sets that overlap by less than a third. So the variance in your "mention rate" is dominated by which paraphrases the tracker happened to pick, not by how AI actually thinks about your brand. You are watching noise and calling it signal.
It gets worse. None of these trackers condition on buyer persona. So "your brand appears 34% of the time" is averaging recommendations to solo founders, enterprise VPs and international SMBs into one number, three completely different distributions collapsed into a single misleading figure. Rank tracking on a fixed prompt set gives you the same false comfort as tracking Google keyword rankings did in 2013. It feels precise. It is not measuring what you think it is.
This is not a fringe view. Cyrus Shepard, Dan Petrovic, Steve Toth and Rand Fishkin have each, in their own way, pushed back on treating a fresh acronym as a fresh discipline, and the empirical research is starting to bear this out. So here is the soundbite I give clients: if your current AEO agency is showing you a rank dashboard on 25 prompts, they are measuring paraphrase artifact and calling it brand signal.
The diagnostic framework I actually run
If your brand is underperforming in AI recommendations, do not buy a tracker and do not commission more content. Diagnose first. This is the sequence I use, in order.
- Find your prominence tier. Where does your brand actually sit on the ladder in your category? This decides which failure modes are even possible for you.
- Isolate the dominant failure mode. Run a small manual audit across five prompt paraphrases and five persona conditions. The pattern of where you appear and vanish tells you which of the five is hurting you most.
- Apply the matching intervention. Discoverability needs authority and indexation. Positioning needs narrative. Persona needs architecture. Match the fix to the failure, not to the invoice.
- Measure the right thing. Track recommendation-set stability across paraphrases and personas, not rank on a fixed prompt. That is the number that actually reflects how AI treats your brand.
The manual audit is simpler than it sounds, and it is the step everyone skips. Take your core buyer query and write it five natural ways a real person would type it. Then run each of those five under five buyer framings: a solo founder, a mid-market marketer, an enterprise buyer, a technical evaluator, and a price-sensitive small business. That is twenty-five prompts, run once, by hand. Where you appear and where you vanish across that grid is your diagnosis. Show up for one phrasing and disappear for the rest, that is prompt-phrasing. Win one persona and lose the others, that is persona. The pattern names the failure for you.
The reason this matters is money. Misdiagnose the failure mode and you can burn six months and a large content budget on the one lever that was never going to move your number. I have watched category leaders commission hundreds of articles to fix what was purely a positioning problem, and regional specialists pay for positioning workshops when they were not even in the retrieval pool yet. The diagnosis is not the boring bit before the real work. It is the work that decides whether the rest is worth doing at all.
Most AI visibility work being sold in 2026 is optimising for the wrong measurement layer. The winning move is not more content or a shinier dashboard. It is diagnosing the actual failure mode and applying the correct per-tier intervention. That is what the next generation of AI SEO consulting looks like, and it is the work I do.
Find your failure mode
Book a 30-minute AI visibility diagnostic call. I will tell you which prominence tier you are on and which of the five failure modes is dominant, before you spend a dollar on the wrong fix.
Book your free AI visibility diagnostic
Want to see where you stand first? Run the free brand AI search visibility check, and read the AI search engines cheatsheet for the mechanics behind all five failure modes.
Frequently asked questions
Why doesn't AI recommend my brand?
For one of five reasons: AI cannot discover you for the query, it discovers you but you lose the shortlist, it names you without picking you, it recommends you to the wrong buyer, or it only recommends you for one phrasing. Being in the model is not the issue. Diagnose which of the five is dominant, then apply the matching fix.
Why isn't ChatGPT recommending my brand?
Usually because you are not in the candidate pool ChatGPT builds when it searches to answer a buyer question, or because you are in the pool but lose the snippet comparison. Getting described accurately when asked directly is not the same as being recommended unprompted. Those are different problems with different fixes.
How do I get recommended by AI?
Diagnose your prominence tier and dominant failure mode first, then apply the right lever: authority and indexation for discoverability, depth and proof for reachability, positioning for being named but not picked, and persona-conditioned content for reaching the right buyer. More generic content rarely fixes it.
Why is my brand missing from AI answers even though the model knows it exists?
Because knowing you exist and recommending you are separate functions. The model can describe you accurately when asked directly and still never surface you for a buyer query, if you are not in the retrieval pool for that query or you do not win the comparison. That gap is the whole game.
Soaring Above Search
Weekly AI search insights from the front line. One newsletter. Six sections. Everything that actually moved this week, with a practitioner's take.

Chief of Staff at StudioHawk, Australia's largest dedicated SEO agency. Specialising in AI search visibility, technical SEO, and organic growth strategy. Leading a team of 120+ across Melbourne, Sydney, London, and the US. Book a free consultation →